1 Généralités
1.1 Définition
En informatique, la sérialisation (de l’anglais américain serialization) est le codage d’une information dans un format qui peut être facilement stocké et transmis. La sérialisation de données au format texte, elle, concerne des fichiers dont le code binaire correspond uniquement à des caractères textuels.
Comme on peut le voir, cette définition repose doublement sur la notion de codage. Le mot codage désigne au sens large le fait de représenter un morceau d’information par un autre. L’informatique met souvent en jeu plusieurs niveaux successifs de codage ; pour la sérialisation de données au format texte, ce sont deux niveaux.
Le premier niveau de codage est lié à la nature matérielle de l’informatique. Il est universel : n’importe quel autre sujet en informatique serait concerné. En effet, dans un ordinateur, le traitement automatique de l’information repose sur un composant de base appelé transistor, qui fonctionne comme un interrupteur : il ne connaît que deux états (ouvert/fermé) et ne peut comprendre qu’une seule instruction (passer d’un état à l’autre). Pour exprimer une information compréhensible par ce dispositif, on doit donc utiliser un alphabet binaire, c’est-à-dire composé de deux caractères seulement (le choix s’est porté sur les chiffres 0 et 1), et établir une convention qui définit quelle succession de ces deux caractères correspond à quelle information. Par exemple, on peut définir que 01100111 signifie g.
Pour les fichiers dont le code binaire correspond uniquement à des caractères textuels, on parle de fichiers au format texte (également : texte brut) ; par caractères textuels, j’entends les caractères d’imprimerie, les caractères d’espacement, les retours à la ligne, etc. Il existe différents codages de caractères, comme ASCII et UTF-8. Les logiciels les plus adaptés pour ouvrir et modifier les fichiers au format texte sont les éditeurs de texte (à ne pas confondre avec les logiciels de traitement de texte). Ils permettent notamment d’afficher le codage utilisé dans le fichier et de passer d’un codage à un autre. Consultez ma page Format texte pour plus d’informations.
Le second niveau de codage est lié à la technique de sérialisation choisie : il s’agit du langage de sérialisation. Pour faciliter le stockage et la transmission d’une information, on lui ajoute des informations supplémentaires qui permettent de préciser sa nature et sa structure. Ces informations sont exprimées sous une forme conventionnelle, codifiée, bref, en respectant un certain codage. Par exemple, on peut définir que <date format="ISO">2022-05-16</date> signifie « 2022-05-16 est une date au format ISO ».
On peut souvent déduire le langage de sérialisation utilisé dans un fichier à partir de l’extension de fichier. Mais ce n’est pas une garantie. La seule méthode fiable pour identifier le langage est d’utiliser un programme capable de le reconnaître (analyseur syntaxique, en anglais parser).
En résumé, lorsqu’on est face à des données sérialisées au format texte, il faut déterminer en premier lieu la manière dont elles sont codées, à deux niveaux :
- quel est le codage de caractères (ASCII, UTF-8…) ?
- quel est le langage de sérialisation (CSV, XML, JSON…) ?
1.2 Fonctionnement
1.2.1 Caractères spéciaux
Un langage de sérialisation au format texte repose sur l’utilisation de certains caractères qui définissent son fonctionnement. On dit de ces caractères qu’ils sont « spéciaux » dans le contexte du langage, car ils sont interprétés pour autre chose que leur signification littérale.
Voici un tableau :
| Codage | Caractère |
|---|---|
| 00100001 | ! |
| 00110011 | 3 |
| 01100111 | g |
Voici les mêmes données, exprimées au format CSV :
Codage,Caractère
00100001,!
00110011,3
01100111,gDans cet exemple, la virgule , est un caractère spécial. Elle ne signifie pas littéralement qu’il y a une virgule : elle indique la séparation entre deux valeurs sur une même ligne. Le retour à la ligne est également un caractère spécial : il indique la séparation entre deux lignes.
1.2.2 Échappement
L’échappement consiste à « neutraliser » des caractères spéciaux pour qu’ils soient interprétés de manière littérale. Ceci permet de gérer le cas où les données contiennent un caractère qui fait partie des caractères spéciaux.
Dans l’exemple ci-dessous (format CSV toujours), la chaîne de caractères Hello, World contient une virgule. Pour éviter que cette virgule ne soit prise pour un caractère spécial, on échappe la chaîne de caractères en la mettant entre guillemets :
heure,message
20:22,Hello World
23:00,"Hello, World."1.2.3 Types de données
Un intérêt de la sérialisation, c’est la possibilité de différencier les données selon leur type. Voici quelques de types de données largement répandus :
| fr | en | exemple |
|---|---|---|
| Chaîne de caractères | string | az09␣&%[<; |
| Nombre entier | integer | 8971 |
| Nombre décimal | float | 0.34 |
| Booléen | boolean | yes no true false |
| Valeur nulle | null | null |
Tous les formats n’incluent pas cette possibilité. Et la manière de déclarer le type de données dépend de chaque format de sérialisation : certains requièrent de déclarer explicitement qu’une donnée est d’un certain type, tandis que d’autres fonctionnent de manière implicite.
1.2.4 Syntaxe
La syntaxe d’un langage de sérialisation correspond à l’ensemble des règles qui régissent l’utilisation des caractères dans le contexte de ce langage. Ceci inclut la définition des caractères spéciaux et la manière de les utiliser, les règles d’échappement, la manière éventuelle d’identifier les types de données, et de manière générale toutes les règles d’écriture qui ont une incidence sur le fonctionnement du langage.
Un programme qui interprète un fichier écrit dans un langage de sérialisation effectue une analyse syntaxique du fichier. Certains programmes ont pour seule fonction de détecter les erreurs de syntaxe : on les appelle des validateurs.
La syntaxe peut être explicitée sous la forme d’une spécification, c’est-à-dire un document établissant de manière canonique les règles formelles du fonctionnement d’un langage. L’existence d’une spécification facilite énormément l’analyse syntaxique, car elle élimine les ambiguïtés dans la définition du fonctionnement du langage et évite ainsi de gérer des variantes dans l’écriture et l’interprétation.
2 CSV
CSV signifie Comma-Separated Values, c’est-à-dire littéralement des valeurs séparées par des virgules. Le principe a été inventé dans les années 1970 et le nom CSV est apparu dans les années 1980.
Exemple de données au format CSV :
Year,Make,Model,Description,Price
1997,Ford,E350,"ac, abs, moon",3000.00
1999,Chevy,"Venture ""Extended Edition""","",4900.00
1999,Chevy,"Venture ""Extended Edition, Very Large""",,5000.00
1996,Jeep,Grand Cherokee,"MUST SELL! air, moon roof, loaded",4799.00CSV sert à exprimer des données tabulaires, limitées à deux dimensions (lignes, colonnes). La première ligne sert généralement à exprimer les en-têtes des colonnes. Chaque ligne est séparée de la précédente par un retour à la ligne. Sur chaque ligne, chaque valeur est séparée de la précédente par une virgule.
Il existe autant de variantes de CSV que de délimiteurs possibles. On trouve ainsi fréquemment des fichiers CSV qui utilisent le point-virgule ou la tabulation à la place de la virgule. Cette diversité peut poser des problèmes lors de l’échange de données, d’autant plus que CSV n’a jamais été fait l’objet d’une spécification unique ni même d’une norme standard (bien qu’il existe un RFC, le 4180).
Parfois, une chaîne de caractères contient le caractère utilisé comme délimiteur. Pour éviter qu’il soit interprété comme faisant partie de la syntaxe du langage, on échappe la chaîne, en indiquant qu’elle doit être lue littéralement. Le RFC 4180 propose une définition standard pour le format CSV dans laquelle l’échappement se fait avec les guillemets ; si une chaîne comprend des guillemets, on fait précéder chacun de ces guillemets d’un autre guillemet.
| Exemple | Échappement |
|---|---|
Hello, World. |
"Hello, World." |
Hello, "World." |
"Hello, ""World.""" |
3 XML
XML signifie eXtensible Markup Language. C’est un format ouvert, standardisé par le W3C.
Exemple de données en XML :
<?xml version="1.0" encoding="UTF-8"?>
<ex:collection xml:lang="fr"
xmlns:dc="http://purl.org/dc/elements/1.1/"
xmlns="http://www.w3.org/1999/xhtml"
xmlns:ex="http://exemple.org">
<élément>Texte</élément>
<dc:title>Astérix le Gaulois</dc:title>
<ex:livre attribut="valeur" type="BD">
<dc:title>Astérix chez les Belges</dc:title>
<dc:creator>René Goscinny</dc:creator>
<dc:creator>Albert Uderzo</dc:creator>
<dc:description>
<b>Astérix chez les Belges</b> est un album de
<a href="http://fr.wikipedia.org/wiki/Bande_dessinée">bande
dessinée</a> de la série Astérix le Gaulois créée par René
Goscinny et Albert Uderzo.
<br />
Cet album publié en 1979 est le dernier de la série écrite
par René Goscinny.
</dc:description>
</ex:livre>
</ex:collection>XML est un cousin de HTML, car il dérive du même langage de balisage de documents, SGML. Mais deux différences importantes le sépare de HTML. D’abord, XML est conçu pour stocker et transporter des données, en mettant l’accent sur ce que sont ces données, alors que HTML est conçu pour afficher des données, en mettant l’accent sur leur apparence. Et ensuite, XML est un méta-langage : le mot « extensible » renvoie au fait qu’il n’y a pas d’éléments XML prédéfinis mais une série de règles de syntaxe qui permettent de créer des langages particuliers avec leurs propres éléments.
XML a été conçu pour être à la fois lisible par l’homme et par la machine, ce qui est nécessairement un compromis sur certains aspects (verbosité, performance).
La liste des usages de XML est longue : langage de balisage, format de données, langage de description de format de document, langage de représentation, langage de programmation, protocole de communication… Quelques exemples de formats basés sur XML :
- XHTML (eXtensible HyperText Markup Language), langage de balisage hypertexte ;
- Docbook, documentation technique, 1991 à 1997 O’Reilly, 1998 à … OASIS ;
- TEI (Text Encoding Initiative), balisage de textes scientifiques, 1987, 1994, 1999, 2002 ;
- EAD (Encoded Archival Description), description archivistique, 1993, 2002, Bibliothèque du Congrès ;
- RDF (Resource Description Framework), réseaux de métadonnées, 1997 à 2006, W3C ;
- RSS (Rich Site Summary, RDF Site Summary et Really Simple Syndication), 1999 à … ;
- Atom Syndication Format, syndication, 2003, IETF ;
- OWL (Web Ontology Language), ontologies, W3C ;
- GML (Geography Markup Language), données géographiques, Open Geospatial Consortium ;
- Dublin Core, bibliographie ;
- EbXML (Electronic Business using eXtensible Markup Language), commerce électronique, OASIS ;
- XBRL (Extensible Business Reporting Language), données comptables ;
- MathML, formules mathématiques, 1999, 2001, 2003, W3C;
- OpenDocument, documents bureautiques ;
- SVG (Scalable Vector Graphics), graphiques vectoriels 2D, 2003, W3C ;
- OAI (Open Archive Initiative), protocole d’archives ouvertes, 2000, 2002, OAI ;
- WebDAV, lecture-écriture distante par HTTP, IETF.
XML est particulièrement présent dans les organisations qui gèrent des documents.
3.1 Syntaxe
- Les documents XML doivent avoir un élément racine.
- Les éléments XML doivent avoir une balise fermante.
- Les balises XML sont sensibles à la casse.
- Les éléments XML doivent être correctement imbriqués.
- Les valeurs d’attribut XML doivent être entre guillemets.
Un document XML est bien formé s’il respecte ces règles syntaxiques de XML. On peut faire un parallèle entre ces règles et l’orthographe en français.
Utilisez un validateur comme celui du W3C pour déterminer si un document XML est bien formé.
3.1.1 Prologue
Le prologue XML est facultatif. S’il existe, il doit venir en premier dans le document. Le prologue XML n’a pas de balise fermante.
Exemple de prologue :
<?xml version="1.0" encoding="UTF-8"?>3.1.2 Élément racine et imbrication
Les éléments XML doivent être correctement imbriqués. Cela signifie simplement que si un élément <sous-enfant> est ouvert à l’intérieur de l’élément <enfant>, il doit être fermé à l’intérieur de l’élément <enfant>. Les documents XML doivent contenir un élément racine qui est le parent de tous les autres éléments.
Exemple :
<racine>
<enfant>
<sous_enfant>...</sous_enfant>
</enfant>
</racine> 3.1.3 Attributs
Les éléments XML peuvent avoir des attributs sous forme de paire nom (d’attribut)-valeur (d’attribut), comme en HTML. En XML, les valeurs d’attribut doivent toujours être entre guillemets.
Exemple :
<sms date="2020-11-07">
<de>Joe</de>
<à>Donald</à>
<texte>covfefe</texte>
</sms> Il n’y a pas de règles sur quand utiliser les attributs ou quand utiliser des éléments dans XML. Mais les attributs ne peuvent pas contenir plusieurs valeurs ni de structure arborescente et ils ne sont pas facilement extensibles. On considère donc généralement qu’il vaut mieux les réserver aux métadonnées (données sur les données), tandis que les données elles-mêmes seront exprimées sous forme d’éléments.
3.1.4 Éléments vides
Un élément vide est un élément qui ne contient pas de données. On peut écrire un élément vide de deux manières : soit comme un élément normal (balise ouvrante et balise fermante), soit avec une balise unique, notée différemment.
Exemple :
<element></element>
<element/>3.1.5 Commentaires
Un document XML peut contenir des commentaires, c’est-à-dire une information qui n’est pas interprétée par la machine mais est plutôt destinée à un lecteur humain. La syntaxe est similaire à celle de HTML.
Exemple :
<!-- Ceci est un commentaire -->3.1.6 Règles de nommage des éléments
Les noms d’élément :
- sont sensibles à la casse ;
- doivent commencer par une lettre ou un tiret du bas ;
- ne peuvent pas commencer par la chaîne de caractères
xml(ouXML, ouXml, etc.) ; - peuvent contenir des lettres, des chiffres, des traits d’union, des traits de soulignement et des points ;
- ne peuvent pas contenir d’espaces.
Les tirets -, points . et deux-points : ne sont pas interdits, mais il vaut mieux éviter de les utiliser car de nombreux logiciels leur attribuent des fonctions spéciales.
3.1.7 Entités
Certains caractères ont une signification particulière en XML. Si vous placez un caractère comme < dans un élément XML, cela générera une erreur car l’analyseur l’interprétera comme le début d’un nouvel élément.
Exemple :
<message>salary < 1000</message>Pour éviter cette erreur, on remplace le caractère < par une entité. Il existe 5 entités prédéfinies en XML :
| Entité | Caractère |
|---|---|
< |
< |
> |
> |
& |
& |
' |
' |
" |
" |
Exemple de XML bien formé :
<message>salary < 1000</message>3.2 Espaces de noms
En informatique, un espace de noms (namespace) désigne un lieu abstrait conçu pour accueillir des ensembles de termes appartenant à un même répertoire. C’est une notion permettant de lever une ambiguïté sur des termes qui pourraient être homonymes. Au sein d’un même espace de noms, il n’y a pas d’homonymes.
XML est un méta-langage. Chaque langage créé avec XML est défini par un ensemble d’éléments. On utilise un espace de noms pour réunir les noms de ces éléments. L’espace de noms est matérialisé dans un document XML par un préfixe et un URL. On ajoute à l’élément racine un attribut xmlns:préfixe (« xmlns » pour « XML namespace ») dont la valeur est un URL. On utilise ensuite le préfixe avant un nom d’élément pour déclarer qu’il appartient à l’espace de noms correspondant. Ce mécanisme permet d’utiliser plusieurs langages XML dans un même document, sans ambiguïté lorsqu’il y a des éléments.
Ci-dessous, l’exemple est un document XML dans lequel se trouve une feuille de transformation XSLT (instructions XML avec le préfixe xsl:) qui prend en entrée un document XML TEI (noms avec préfixe tei:) et donne en sortie du HTML (noms sans préfixe, comme abbr) :
<?xml version="1.0" encoding="UTF-8"?>
<xsl:transform
version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:tei="http://www.tei-c.org/ns/1.0"
xmlns="http://www.w3.org/1999/xhtml"
>
<xsl:template match="tei:abbr">
<abbr>
<xsl:apply-templates/>
</abbr>
</xsl:template>
</xsl:transform>3.3 Modèles de documents
En XML, le vocabulaire (noms d’éléments et d’attributs) et la grammaire (règles d’écriture) ne sont pas définis a priori. Ces règles s’expriment en un schéma de document, qui permet notamment de valider automatiquement un document sur sa conformité à ce modèle. Contrairement à son ancêtre SGML, XML accepte plus d’une syntaxe : on peut écrire des modèles en DTD, XML Schema, Relax NG ou encore Schematron.
3.3.1 DTD
Une définition du type de document (Document Type Definition, DTD) est un fichier qui indique des règles d’écriture pour des fichiers XML. C’est le mécanisme le plus ancien, hérité du langage SGML, dont XML est dérivé. Les DTD sont simples mais limitées.
Une DTD est constituée le plus souvent de déclarations d’éléments et d’attributs. D’autres types de déclaration existent (entités, notations) mais correspondent à une utilisation plus avancée et ne sont pas abordées ici. Un exemple de DTD :
<!DOCTYPE book [
<!ELEMENT book (#PCDATA | em | cite)*>
<!ELEMENT em (#PCDATA)>
<!ELEMENT cite (#PCDATA)>
]>Un fichier XML est dit valide s’il respecte cette DTD. Exemple de XML valide par rapport à la DTD précédente :
<book>
Du <em>texte</em> et une <cite>citation</cite>.
</book>Les DTD sont encore utilisées dans certains systèmes mais ont été progressivement remplacées par les schémas XML.
3.3.1.1 Déclaration de la DTD
DTD interne au fichier XML (root-element correspond au nom de l’élément racine) :
<!DOCTYPE root-element [ declarations ]>DTD externe (url correspond au chemin du fichier) :
<!DOCTYPE root-element SYSTEM "url">3.3.1.2 Déclaration d’élément
<!ELEMENT element type>Opérateur | Signification :——-: | :———— , | Mise en séquence | | Choix ? | 0 ou 1 occurrence * | Répétition d’un nombre quelconque d’occurrences + | Répétition d’un nombre non nul d’occurrences
Exemples :
<!ELEMENT elem (elem1, elem2, elem3)>
<!ELEMENT elem (elem1 | elem2 | elem3)>
<!ELEMENT elem (elem1, elem2?, elem3)>
<!ELEMENT elem (elem1, elem2*, elem3)>
<!ELEMENT elem (elem1, (elem2 | elem4), elem3)>
<!ELEMENT elem (elem1, elem2, elem3)*>
<!ELEMENT elem (elem1 | elem2 | elem3)*>
<!ELEMENT elem (elem1 | elem2 | elem3)+>Contenu textuel :
<!ELEMENT element (#PCDATA)>Contenu mixte :
<!ELEMENT element (#PCDATA | element1)*>Contenu vide :
<!ELEMENT element EMPTY>Contenu libre :
<!ELEMENT element ANY>3.3.1.3 Déclaration d’attribut
Syntaxe :
<!ATTLIST element attribut type valeur-par-default>Types d’attributs les plus courants :
- CDATA
- (value-1 | value-2 | … | value-N)
- ID
Type de valeur par défaut :
"value"ou'value'#IMPLIED#REQUIRED#FIXED "value"ou#FIXED 'value'
3.3.2 Schémas XML
L’autre mécanisme, qui tend à remplacer les DTD, ce sont les schémas XML (en anglais : XML Schema). Les schémas sont polyvalents, ils permettent de décrire finement les règles d’écriture de fichiers XML. Par conséquent, ils sont complexes.
Exemple de schéma XML :
<?xml version="1.0" encoding="UTF-8"?>
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema">
<xs:element name="personne">
<xs:complexType>
<xs:sequence>
<xs:element name="nom" type="xs:string" />
<xs:element name="prenom" type="xs:string" />
<xs:element name="date_naissance" type="xs:date" />
</xs:sequence>
</xs:complexType>
</xs:element>
</xs:schema>4 JSON
JSON signifie JavaScript Object Notation. C’est un format ouvert et standardisé, couramment utilisé dans les échanges de données entre client et serveur.
Exemple de données en JSON :
{
"@context": "https://schema.org/",
"@type": "Recipe",
"name": "Party Coffee Cake",
"author": {
"@type": "Person",
"name": "Mary Stone"
},
"recipeIngredient": [
"2 cups of flour",
"3/4 cup white sugar",
"2 teaspoons baking powder",
"1/2 teaspoon salt",
"1/2 cup butter",
"2 eggs",
"3/4 cup milk"
]
}La présence du nom JavaScript dans le nom de JSON est légèrement trompeuse : si l’origine de JSON est bien liée au langage de programmation JavaScript, les deux sont complètement indépendants.
Les inventeurs de JSON, Douglas Crockford et Chip Morningstar, étaient à la recherche d’un mécanisme de transmission de données qui soit interopérable, c’est-à-dire qui fonctionne indépendamment du navigateur (à l’époque les principaux étaient Internet Explorer et Netscape). Ils ont décidé d’utiliser JavaScript pour ne pas avoir à inventer un nouveau langage et un analyseur pouvant l’interpréter.
En JavaScript, un objet est une structure de données. Par opposition aux variables, qui ne peuvent contenir qu’une valeur, les objets peuvent contenir plusieurs valeurs. Un objet est délimité par des accolades {}, et contient des paires clé-valeur séparées par des virgules.
Exemple de définitions d’un objet person en JavaScript :
var person = { firstName: "James" };
var person = {
firstName: "James",
lastName: "Bond",
age: 41,
}; Crockford et Morningstar ont imaginé un script qui utilise la syntaxe des objets en JavaScript pour envoyer des données via un navigateur. Voici leur script :
<html><head><script>
document.domain = 'fudco';
parent.session.receive(
{
to: "session",
do: "test",
text: "Hello world"
}
)
</script></head></html>Ils ont alors rencontré un problème : do est un mot réservé pour une fonction spéciale en JavaScript, et ne peut donc pas être utilisé comme clé dans une paire clé-valeur. Crockford et Morningstar ont décidé de contourner le problème en convenant que les clés soient toujours entre guillemets, et c’est ainsi qu’a commencé la formalisation de la syntaxe de JSON.
4.1 Syntaxe
Le site officiel de JSON explique la syntaxe de JSON sous forme de diagrammes particulièrement ingénieux.
- Objet
-
Un objet est un ensemble de couples nom/valeur non ordonnés. Un objet commence par une accolade gauche
{et se termine par une accolade droite}. Chaque nom est suivi d’un deux-points:et les couples nom/valeur sont séparés par une virgule.
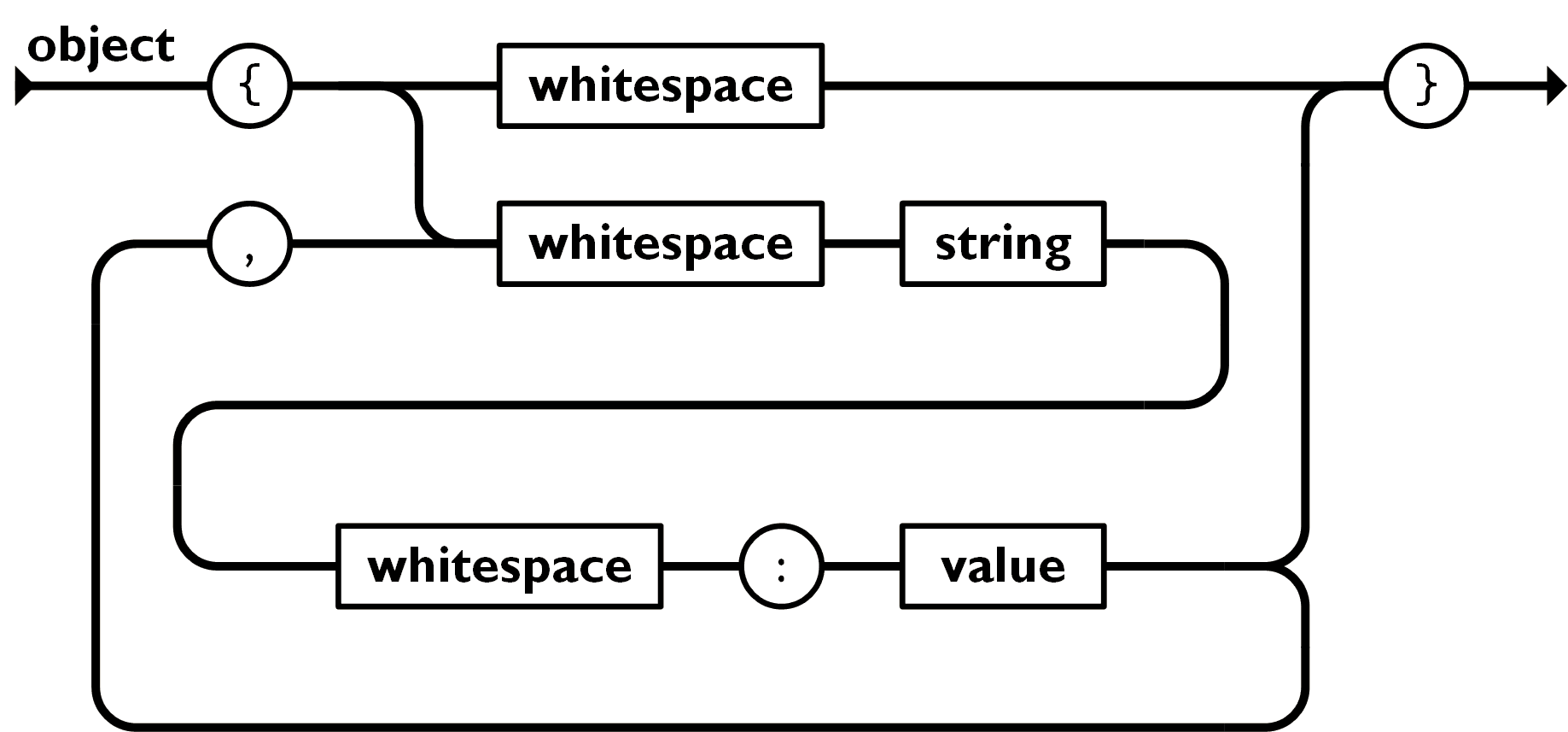
Le mot whitespace désigne les caractères d’espacement (« blancs », « invisibles ») : espace, tabulation, retour à la ligne, etc.
JSON ignore les caractères d’espacement utilisés en-dehors des noms et des valeurs. On les utilise alors plutôt pour embellir (beautify) le code sur lequel on travaille (pour un meilleur confort visuel), et on les retire une fois le travail terminé pour réduire (minify) le nombre de caractères, ce qui diminue le volume du fichier. Certains outils d’analyse syntaxique de JSON, comme le service en ligne JSON Formatter, proposent des fonctionnalités qui automatisent ces différentes actions.
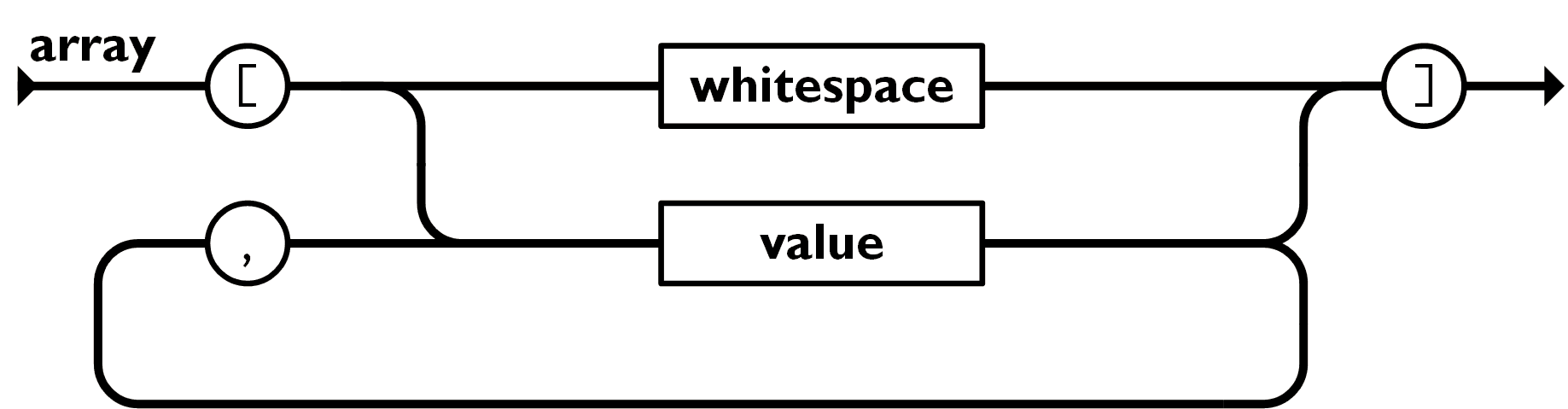
- Array
-
Un array est une collection de valeurs ordonnées. Un array commence par un crochet gauche
[et se termine par un crochet droit]. Les valeurs sont séparées par une virgule.
- Valeur
-
Une valeur peut être soit une chaîne de caractères entre guillemets, soit un nombre, soit un booléen
trueoufalse, soit la valeur nullenull, soit un objet soit un array. Ces structures peuvent être imbriquées. Une chaîne de caractères est une suite de zéro ou plus caractères Unicode, entre guillemets, qui utilise éventuellement des échappements avec barre oblique inverse.
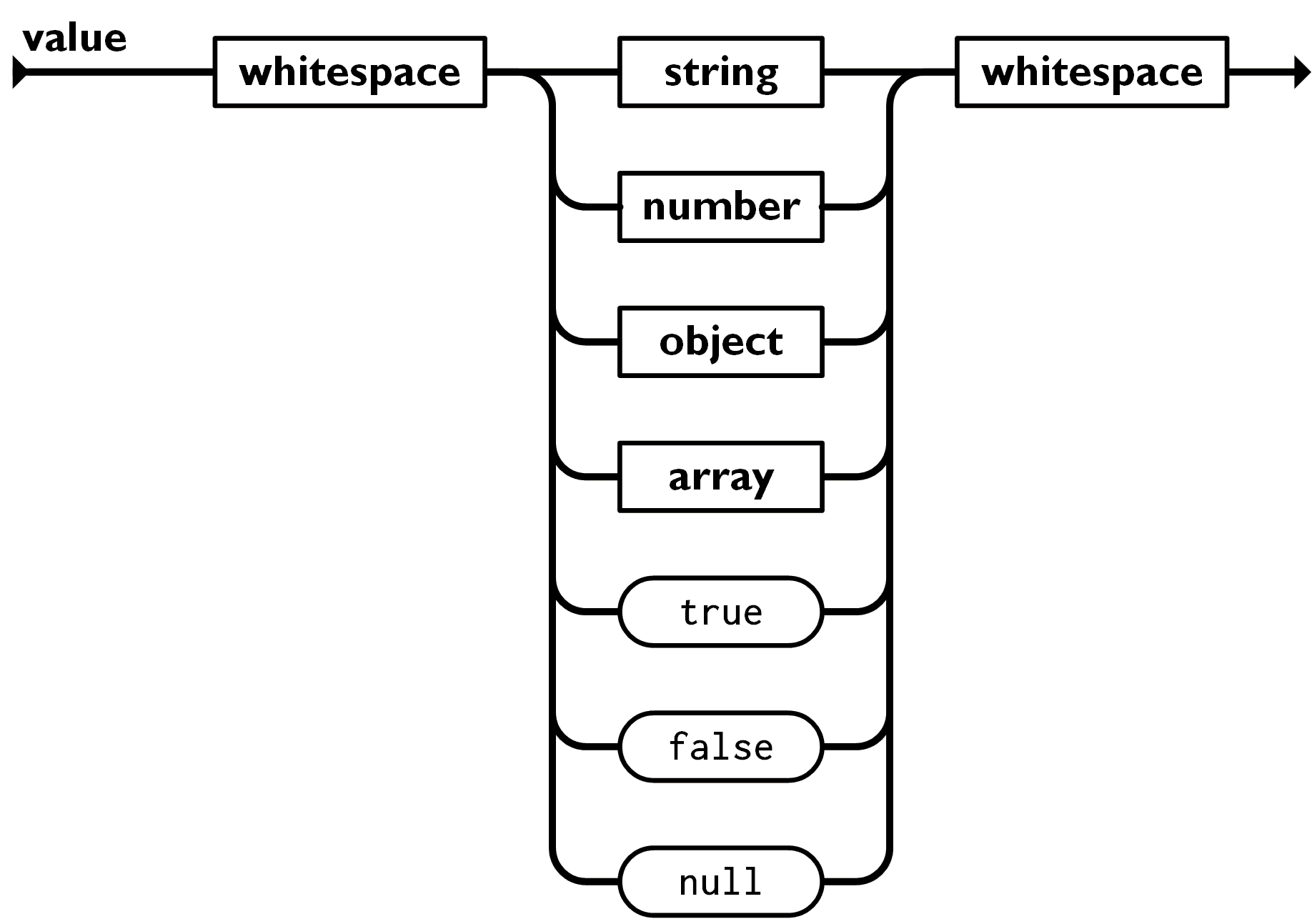
Le principe de l’échappement s’utilise aussi en JSON. Combiné à certaines lettres définies par avance (comme b ou n), l’échappement permet de créer une séquence de deux caractères qui sera interprétée et remplacée par le caractère Unicode correspondant. Exemple : \n équivaut à un retour à la ligne (n pour newline).
5 YAML
YAML (YAML Ain’t Markup Language) est un langage dérivé de JSON qui privilégie la lisibilité et l’écriture par les humains plutôt que par les machines. Sa caractéristique la plus reconnaissable est la possibilité de structurer les données en utilisant des caractères d’espacement, notamment des espaces en début de ligne (indentation) pour représenter visuellement la hiérarchie des données.
Exemple de données en YAML :
name: John Smith
age: 26
hobbies:
- sports
- cooking
manager:
name: Jon Doe
age: 45
hobbies:
- fishing
manager: ~Les mêmes données en JSON, embellies avec des caractères d’espacement :
{
"name":"John Smith",
"age":26,
"hobbies":[
"sports",
"cooking"
],
"manager": {
"name":"Jon Doe",
"age":45,
"hobbies":[
"fishing"
],
"manager":null
}
}La syntaxe de YAML a pour but de faciliter l’écriture et la lecture des fichiers par des humains, en allégeant visuellement le code et en ajoutant la possibilité de mettre des commentaires ou encore d’écrire sur plusieurs lignes. En contrepartie, cela nécessite beaucoup plus de règles formelles et cela augmente le travail des machines, car l’analyse syntaxique est plus difficile.
YAML est techniquement un sur-ensemble strict de JSON. En informatique, un sur-ensemble (superset) est un langage basé sur un autre langage auquel il ajoute des fonctionnalités supplémentaires. Cela signifie qu’un analyseur YAML peut lire du YAML et du JSON. En revanche, un analyseur JSON ne peut pas lire de YAML, seulement du JSON.