Sémantique et mise en forme, ouvrir la boîte de Pandoc ?
Ce texte creuse le sillon amorcé dans un précédent billet sur les questions d’écriture scientifique. Il s’agit cette fois-ci de s’intéresser à la forme, en montrant combien il est délicat de la dissocier des questions de sémantique.
De l’écriture avant toute chose
Depuis leur informatisation, les outils d’écriture scientifique suscitent le débat. Plus qu’une querelle d’usagers ou un débat de machine à café, il s’agit d’une véritable interrogation épistémologique soutenue par des appels plus que convaincants à remettre en question nos préconceptions.
Sur le sujet, je recommande chaudement la double lecture des articles Les chercheurs en SHS savent-ils écrire ? et En finir avec Word !
Une communauté grandissante d’auteurs scientifiques cherchent à utiliser des outils plus efficaces, interopérables et pérennes, sans sacrifier ni le confort de travail et la qualité de la publication. Et la préoccupation première doit bien être l’écriture :
« Mon conseil : tout ce dont vous avez besoin pour écrire est un programme qui vous permet d’écrire du texte dans un fichier […] Vous ne devriez pas avoir à vous soucier de comment vous mettez le texte dans le fichier, mais seulement de quel texte. Une fois que vous pouvez faire cela confortablement, continuez de le faire. Et continuez encore. Quand vous obtenez quelque chose de publiable, alors seulement vous pouvez commencer à vous soucier des outilsThorsten Ball, The Tools I Use To Write Books.
».
Il s’agit donc moins d’une histoire de comment que de quoi. C’est la raison pour laquelle certains auteurs se tournent vers des technologies permettant de dissocier le fond et la forme, privilégiant une réflexion sur le sens et la structure avant toute chose.
Fond et forme
J’ai évoqué précédemment une ébauche de système d’écriture scientifique basé sur le balisage léger, en puisant dans des méthodes publiées sur le Web.
Le blog Zotero francophone a publié entretemps un billet exemplaire qui détaille à la fois les éléments conceptuels et techniques du système. J’invite tous les lecteurs de passage à s’y référer pour le mettre en place chez eux et/ou compléter leurs lectures sur le sujet.
Mes expérimentations s’appuient exactement sur les composants listés dans l’article :
- un langage pour structurer son propos (Markdown) ;
- des outils pour gérer ses références bibliographiques et faciliter la citation (Zotero avec BetterBibTeX et Zotpick) ;
- un convertisseur pour générer des documents publiables (Pandoc).
Toutefois, l’article ne s’étend pas beaucoup sur les formats de sortie, ce qui soulève un problème : une fois la question du fond réglée, il ne faut pas pour autant oublier de proposer des éléments sur la forme…
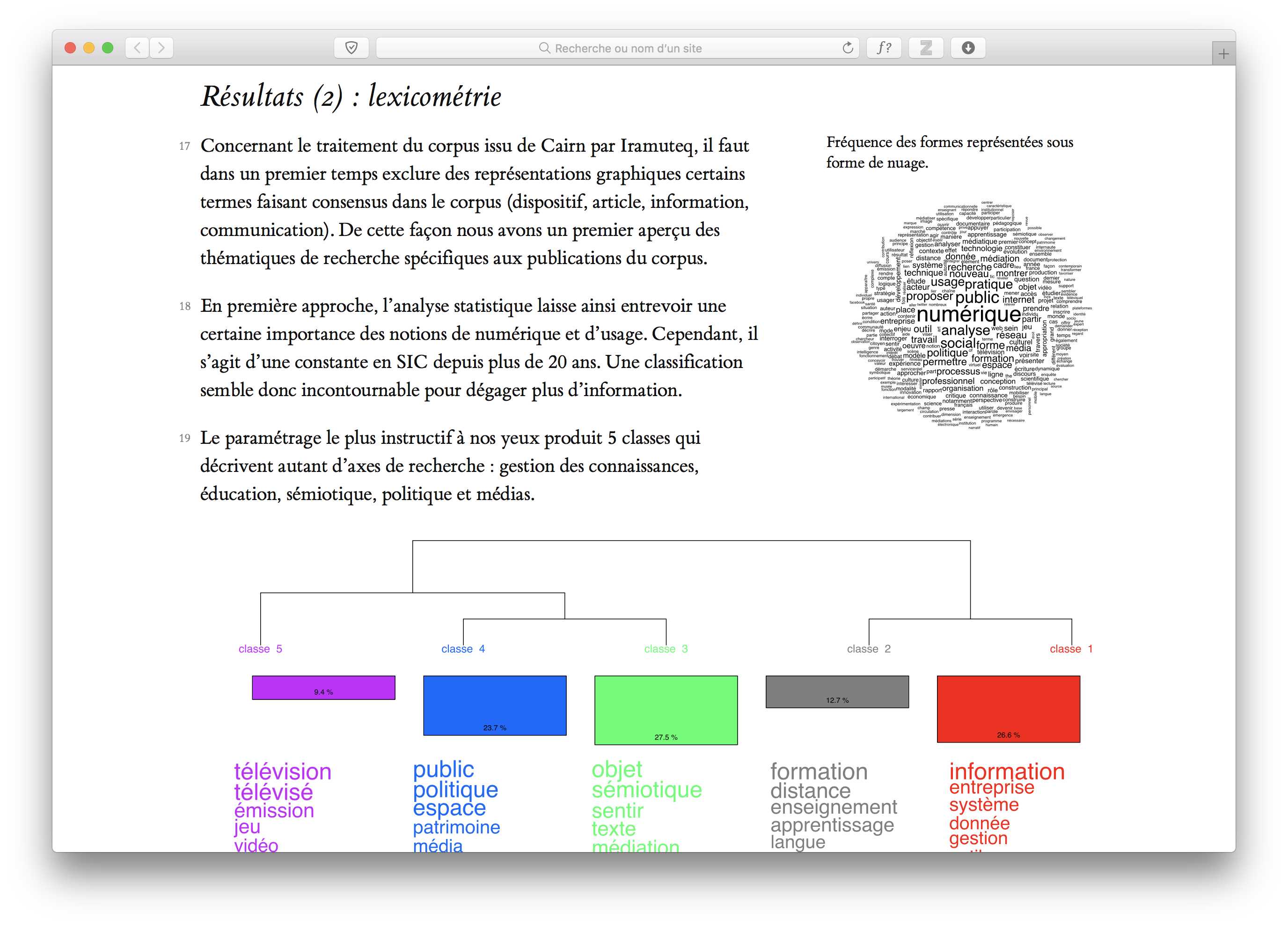
Les auteurs ont pris soin de lister plusieurs outils pour différents contextes (pédagogie, publication), en soulignant la simplicité des options de mise en page, mais à mon sens cela évacue la question sans l’aborder. Le problème est que l’auteur doit quand même mettre les mains dans le cambouis du traitement de texte ou du balisage lourd s’il veut réaliser le moindre choix de mise en page (polices, couleurs, placement des figures, marges…).
On ne peut pas suggérer une alternative à Word en ne proposant que 50% de ce que permet le logiciel de Microsoft. Nos propositions en matière de sémantique sont cruciales, car c’est ce qui demande le plus d’efforts de transformation aux usagers. Mais il ne faut pas jeter la stylistique avec l’eau du WYSIWYG.
Organiser l’espace
Pour la rédaction de mon mémoire de master, j’ai adopté une classe LaTeX reproduisant la mise en page des livres d’Edward Tufte. J’y reviens sans cesse, en essayant de la décliner sous toutes les formes pertinentes.
Tufte est un statisticien américain, professeur de sciences politiques, qui s’est distingué par ses travaux en design de l’information. Discutant de ses inspirations dans un post sur le forum de son site, il écrit :
« Il est remarquable que le Cours de physique de Feynman (3 volumes) englobe toute la physique en 1800 pages, en utilisant seulement 2 catégories de titres hiérarchiques : les chapitres et les en-têtes de premier niveau au sein du texte. De plus, il privilégie une construction méthodique par phrases qui se cumulent ensuite en paragraphes, plutôt qu’un bataillon de listes à puces. Si complexe que soit la physique de premier cycle enseignée à Caltech, elle ne nécessite pas pour autant une hiérarchie très élaboréeEdward Tufte, “Book design: advice and examples”.
».
Tufte évoque ici l’importance des choix de structuration du texte, sous-entendant qu’une bonne partie de nos problèmes documentaires partent de mauvais choix d’écriture.
Or ce n’est pas qu’une simple question de titres ou de paragraphes : l’appareil critique (notes, citations) doit lui aussi être pensé, de même que les figures, les tableaux, les extraits de code, etc. Ce sont tous des éléments de contenu, dont l’encodage sémantique est loin d’être évident : dès que l’on sort du corps de texte, l’agencement des éléments n’est plus un problème linéaire mais arborescent. La dimension spatiale s’impose. Face à ces problèmes, deux stratégies se développent : renoncer à trouver une solution ou bien se jeter la tête la première dans le terrier du lapin blanc.

Pour ses livres, Tufte a développé au fil des ans un style éditorial très inspiré de ce commentaire sur le Cours de Feynman. C’est une mise en page en une colonne de texte, encadrée par des marges asymétriques — l’une étant beaucoup plus large que l’autre et accueillant des notes, des citations, des figures ou des tableaux. Tufte peuple cette marge de tant d’éléments qu’elle fait presque figure de seconde colonne. L’objectif est double : préserver la lecture du texte, qui n’est plus interrompue mais ponctuée naturellement par un décalage du regard ; et optimiser la gestion de l’espace dans des documents particulièrement chargés en contenu.
Ce principe de mise en page est redoutablement efficace. La notoriété de Tufte en informatique fait qu’il a été implémenté successivement par différentes communautés : d’abord des classes de document pour LaTeX, ensuite une CSS et des règles d’écriture pour le format HTML, puis un module pour l’intégration dans RStudio et enfin un filtre Pandoc accompagné de quelques adaptations de la syntaxe Markdown. Ces différents projets peuvent notamment se trouver à partir d’un dépôt Github dédié.
La CSS est remarquable, étant intégralement adaptative (responsive). Figures et tableaux sont redimensionnés à la volée en fonction de la taille de la fenêtre ou de l’écran. Lorsque celle-ci se réduit, les éléments en marge s’intègrent sous forme d’appels clicables au fil du texte ; au besoin, le lecteur peut les afficher, avec un effet qui évoque un coup d’œil à travers des persiennes.
Implémentation multi-canal
Le « style Edward Tufte » n’est qu’une proposition éditoriale parmi d’autres, mais qui constitue une opportunité intéressante : elle est intrinsèquement adaptée à l’écrit scientifique et connaît plusieurs développements dans des technologies compatibles avec les principes discutés plus haut.
Vous me voyez venir. Le rêve éditorial consiste à réaliser une intégration complète des différents outils pour un style donné : une chaîne qui permette de produire des documents pour traitement de texte, des PDF, des pages Web et des présentations à partir d’un seul et unique environnement d’écriture. Un fichier en Markdown et un kaléidoscope de sorties documentaires toutes savamment construites suivant un principe élégant et homogène. La synthèse de cette tendance sémantique qui se renforce d’année en année et d’un écosystème de technologies d’édition arrivées à maturité.
Je ne suis pas en mesure de montrer la réalisation exhaustive de ce rêve mais au moins un bon début. Voici un exemple dont le contenu a seulement caractère d’illustration. On retrouve les excellentes possibilités d’intégration des figures propres à la mise en page de Tufte :
 L’export vers les traitements de texte est l’occasion de revoir mes ambitions à la baisse. Une mise en page beaucoup plus classique, mais plus simple à mettre en œuvre, plus interopérable également.
L’export vers les traitements de texte est l’occasion de revoir mes ambitions à la baisse. Une mise en page beaucoup plus classique, mais plus simple à mettre en œuvre, plus interopérable également.
Tout ceci repose sur Pandoc et le système expliqué dans mon billet précédent ainsi que celui du blog Zotero. Il s’agit de commandes Pandoc survitaminées, intégrant de multiples options pour articuler les différents fichiers : modèles (.css .docx .tex) ; bibliographie (.bib .csl) ; les scripts, l’huile dans les rouages… (--filter) ; la portabilité (--standalone, --self-contained).
Les commandes Pandoc correspondant à chaque export peuvent être emboîtées dans une petite application et un hot folder peut être utilisé pour faciliter les conversions. Le tout peut être copié, réécrit et adapté sur n’importe quel machine. À titre indicatif, mon application « Pantufte » exécute le script suivant :
title=$(basename "$@" .md)
pandoc "$@"
-f markdown+smart
-t html5
-o /Users/arthurperret/Desktop/Conversions/"$title".html
--template=tufte
--section-divs
--filter pandoc-sidenote
--self-contained
--filter pandoc-citeproc
--bibliography=biblio.bib
--csl=apa.csl
-c /Users/arthurperret/Code/CSS/tufte.css
-c /Users/arthurperret/Code/CSS/tufte-extra.css
-c /Users/arthurperret/Code/CSS/pandoc.css
-c /Users/arthurperret/Code/CSS/pandoc-solarized.css
open /Users/arthurperret/Desktop/Conversions/"$title".htmlLe problème évident est que l’on arrive ici sur le terrain de l’expertise éditoriale : le niveau de sophistication de la mise en page rehausse mécaniquement le seuil de compétences nécessaire pour la travailler.
À terme, la mise à disposition d’une telle chaîne documentaire nécessiterait un travail collaboratif, une vraie documentation, un dépôt de code, etc.
En effet, les modèles prennent une grande importance et nécessitent beaucoup plus de travail. Les CSS sont plus denses ; le gabarit Word doit être finement ajusté ; le modèle LaTeX doit être profondément travaillé. En si peu de mots, j’ai résumé des heures et des heures d’élaboration, de test, de frustration et de satisfaction. Je ne me voile pas la face sur le caractère hautement spécifique de la tâche.
Par ailleurs, l’introduction de variantes dans la syntaxe Markdown pour les figures met par terre une bonne partie du travail effectué sur le workflow générique, basé sur les modèles fournis avec Pandoc. C’est un défaut majeur d’un point de vue architectural, qui fait regretter à certains l’absence de syntaxe canonique. Pour être contourné, ce problème requiert des compétences en programmation, afin d’automatiser l’adaptation de la syntaxe d’un format de sortie à l’autre (soit de façon crasseuse en Python avec des expressions régulières, soit par des filtres JSON injectés dans la commande Pandoc). Si cela vous inquiète, tout est normal. Si cela vous enthousiasme, rentrons en contact.
Et maintenant ?
Face à ce constat, quelle peut être mon intention en partageant une telle expérience ?
Une fois de plus, répéter à quel point la reprise en main des outils est incontournable. Des solutions intégrées existent déjà (le blog Zotero recommande notamment Authorea) et d’autres émergeront sans doute dans les années à venir. Mais pour amorcer un véritable tournant info-communicationnel dans le milieu scientifique, il faut expérimenter sur les formats, les langages et les outils.
Pandoc, le « couteau-suisse de l’édition », s’avère précieux. Il rend possible la création de chaînes légères, génériques et adaptables, faciles à déployer et enseigner ; il permet également la mise en place de chaînes sophistiquées, requérant des compétences éditoriales avancées, sans toutefois sacrifier leur reproductibilité.
Couplée à l’émergence de l’Open Access et sous réserve que la question de l’accès aux études fasse l’objet de proposition plus humanistes et moins étriquées que celles actuellement en vogue, cette reprise en main laisse espérer de belles choses.